
Decision tree algorithm implementation using diabetic dataset in python:
Decision tree algorithm is a supervised learning algorithm, and it is used for both classification and regression problems. It is called decision tree because it all starts with root node and like a tree it branches off into a sub tree. Based on some conditions the decisions are made and it branches off.
Decision Tree algorithm

Terminologies in decision tree:
Splitting - The process of splitting the root node or the decision node is called as splitting.
Branch/Sub tree - The tree formed after splitting is called branch or sub tree.
Pruning - The process of removing unwanted branches from the tree is called as pruning.
Parent node/child node - The root node is called as parent node and the decision nodes and leaf nodes are called as child nodes.
Information gain:
Information gain shows how much information a feature gives about the class. The attribute with highest information gain is split first. The value of the information gain is always maximized by the decision tree algorithm.
Information gain is calculated by using the formula given below.
Information gain=E parent-E children
Where E parent is the entropy of the parent node and E children is the average entropy of the child nodes.
Entropy:
Entropy is used to measure the impurity of the attributes.
Entropy= -P (yes) log2 P(yes)- P(no) log2 P(no)
Gini Index:
To measure the impurity or purity while creating the decision tree in CART algorithm Gini index is used. CART algorithm is the classification and regression tree algorithm. It is mainly used for binary splits. Attribute with low gini index is always preferred when with high gini index attributes.
Advantages and disadvantages of decision tree:
For decision making this algorithm is very useful. The process is same as the human thought process. The disadvantage is, it consists of many layers, so the process is very complex.
Decision Tree Implementation in python using Diabetics dataset:

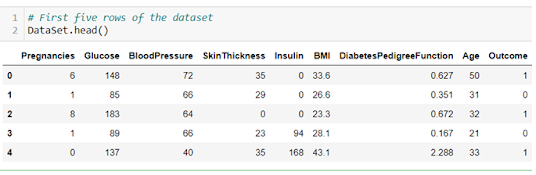
First five rows of the dataset:
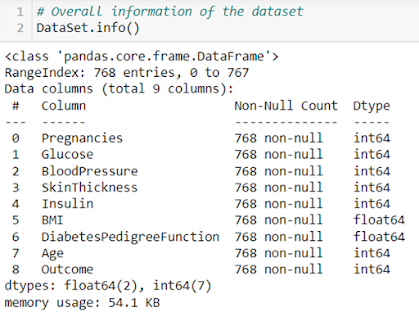
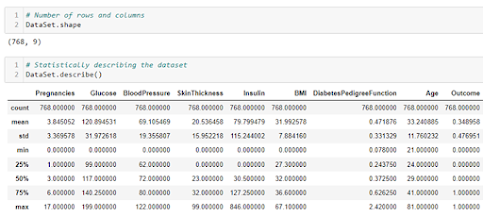
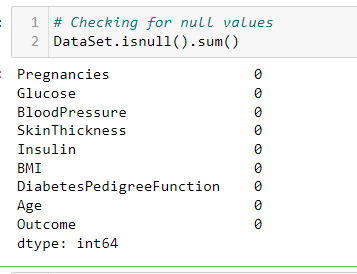









0 Comments